Theoretical Motivations for Deep Learning
rinuboney.github.ioThere is a recent 5 page theoretical paper on this topic that I thought was pretty interesting, and it tackles both deep nets and recurrent nets: http://arxiv.org/abs/1509.08101
Here is the abstract:
This note provides a family of classification problems, indexed by a positive integer k, where all shallow networks with fewer than exponentially (in k) many nodes exhibit error at least 1/6, whereas a deep network with 2 nodes in each of 2k layers achieves zero error, as does a recurrent network with 3 distinct nodes iterated k times. The proof is elementary, and the networks are standard feedforward networks with ReLU (Rectified Linear Unit) nonlinearities.
1) I am curious about learning more about the statement: "Deep learning is a branch of machine learning algorithms based on learning multiple levels of representation. The multiple levels of representation corresponds to multiple levels of abstraction. "
What evidence exists that the 'multiple levels of representation', which I understand to generally be multiple hidden layers of a neural network, actually correspond to 'levels of abstraction'?
2) I'm further confused by, "Deep learning is a kind of representation learning in which there are multiple levels of features. These features are automatically discovered and they are composed together in the various levels to produce the output. Each level represents abstract features that are discovered from the features represented in the previous level. "
This implies to me that this is "unsupervised learning". Are deep learning nets all unsupervised? Most traditional neural nets are supervised.
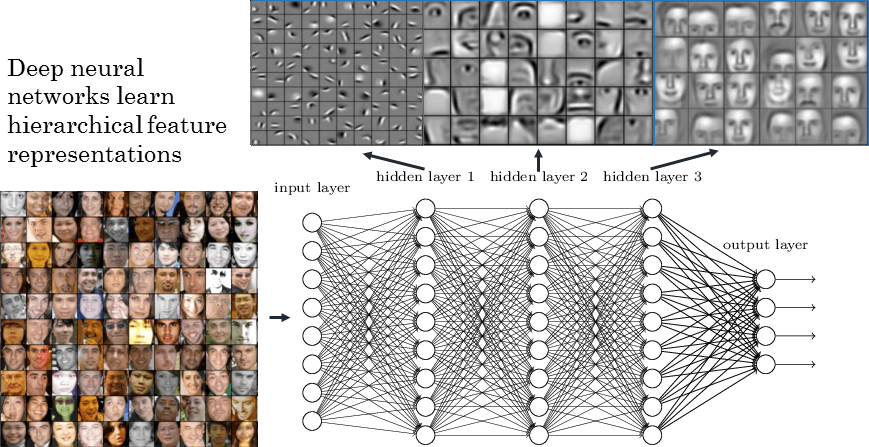
1) The evidence is that when you for instance visualize the features learned in the layers of a deep convolutional neural net, you'll see that these correspond to layers of abstraction, with each layer's features building upon concepts from the previous layer(s). I found an image [0] (on a site [1]) that illustrates it nicely.
2) Deep learning is really a term that denotes machine learning using models that attempt to abstract the data via multiple layers (popularly in artificial neural networks). Not all deep neural nets are unsupervised, but unsupervised pre-training [2] was an approach that was [3] very popular until dropout [4,5] (and its variations) appeared. See, for instance, some of the standard datasets [6] of the field, on some of which deep neural nets achieved state of the art accuracy using supervised learning.
[0]: http://www.rsipvision.com/wp-content/uploads/2015/04/Slide6....
[1]: http://www.rsipvision.com/exploring-deep-learning/
[2]: https://www.youtube.com/watch?v=Oq38pINmddk
[3]: http://fastml.com/deep-learning-these-days/
[4]: http://arxiv.org/pdf/1207.0580.pdf
[5]: http://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
The whole presentation seems very hand-wavy, which I think is pretty much the level most motivational discussions of deep learning are at.
I think the presentations by Yann Lecun and Leon Bottou are more interesting - and tend to involve more uncertainty and fewer pronouncements.
This was fascinating and greatly informative. As you said, the authors were not afraid to show the real warts and bleeding edge, as a good scientist should. Thanks for the link.
{kind=link}
I wonder if "lots of data" is wrong. If I show you say twenty similar-looking Chinese characters in one person's handwriting, and the same twenty in another person's handwriting, you'll probably do a good job (though maybe not an easy time) classifying them with very little data.
Because I've seen lots of other handwriting, even if in another language. I have very strong priors.
The problem is that a computer comes in without knowing anything about tangential phenomenon. So it needs lots of data to catch up to me and my years of forming associative connections about other handwriting I've seen.
If I showed you alien (ie not human) handwritten samples, you'd probably stuggle too.
"you'll probably do a good job classifying them with very little data."
It's because we use much better algorithms in our brains (compared to the ones we currently have in DL). Having "lots of data" allows us to get good results even while using inferior algorithms.
A baby who's never seen an image before wouldn't be able to do that. It wouldn't even know what writing is.
What tools did you use to make those nice pictures?
(didn't read it yet though, will do when I have time)
Nice. Very well organized.