Deprecating our AJAX crawling scheme
googlewebmastercentral.blogspot.comDon't believe the hype. Google has been saying that they can execute javascript for years. Meanwhile, as far as I can see, most non-trivial applications still aren't being crawled successfully, including my company's.
We recently got rid of prerender because of the promise from the last article from google saying the same thing [1]. It didn't work.
1: http://googlewebmastercentral.blogspot.com/2014/05/understan...
Todd from Prerender.io here. We've seen the same thing with people switching to AngularJS assuming it will work and then coming to us after they had the same issue.
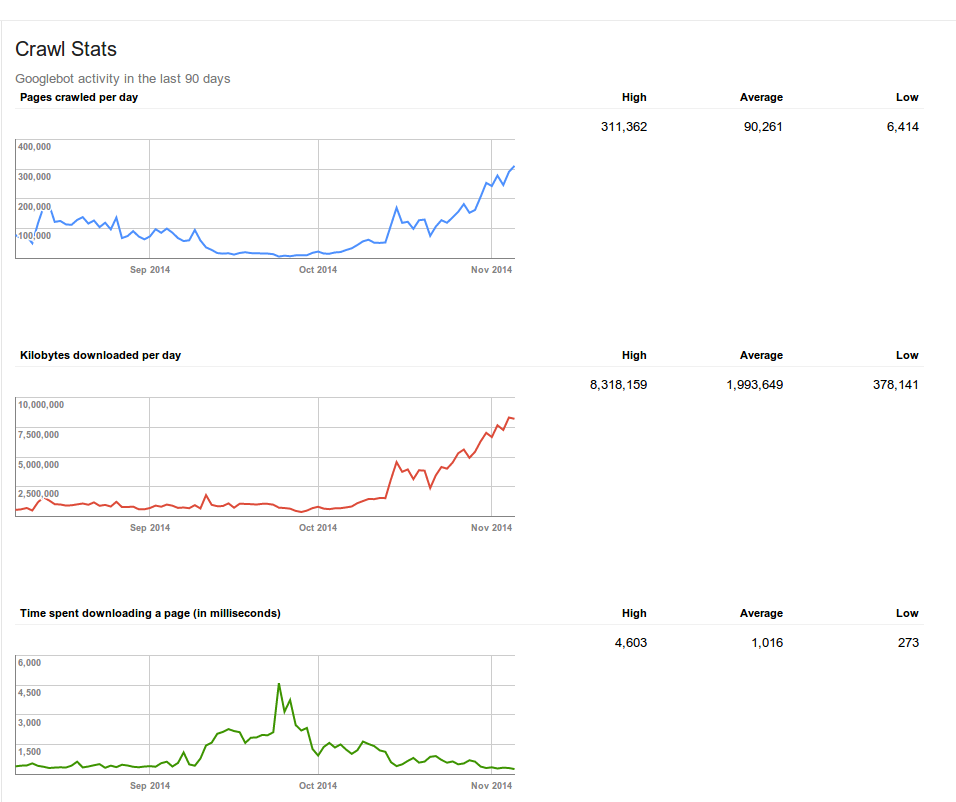
[1] This image is from 2014, when Google previously announced they were crawling JavaScript websites, showing our customer's switch to an AngularJS app in September. Google basically stopped crawling their website when Google was required to execute the JavaScript. Once that customer implemented Prerender.io in October, everything went back to normal.
Another customer recently (June 2015) did a test for their housing website. They tested the use of Prerender.io on a portion of their site against Google rendering the JS of another portion of their site. Here are the results they sent to me:
Suburb A was prerendered and Google asked for 4,827 page impressions over 9 days Suburb B was not prerendered and Google asked for 188 page impressions over 9 days
We've actually talked to Google some about this issue to see if they could improve their crawl speed for JavaScript websites since we believe it's a good thing for Google to be able to crawl JavaScript websites correctly, but it looks like any website with a large number of pages still needs to be sceptical about getting all of their pages into Google's index correctly.
1: https://s3.amazonaws.com/prerender-static/gwt_crawl_stats.pn...
Perhaps this could be down to response times too, they might crawl much quicker if given static HTML very quickly?
What were the page render times for the two types of page?
Interesting will have to reinvestigate this
I noticed our companies Ember.js based SPA site not being indexed well until I added a sitemap. Then it quickly appeared in the rankings.
Historically Google has been using some fork of Chrome 10 when indexing. I'm unsure what impact that is having on the reliability of app rendering, but I also trust the Google search team has done reasonable checks ensuring common sites and frameworks render correctly.
I strongly suggest using a sitemap for JS rendered sites, based on my own experience.
It's also worth noting that even when they do get JS delivered content, it updates much less frequently...
Then again, I really like react+redux+koa (r3k) for client-server rendering.... Hoping to do something more serious with it in the next few months at work.
{kind=link}
So they're actually evaluating all js and css Googlebot is consuming. That's insane.
Can we forget about any new competitors in search engine land now? Not only do you have to match Google in relevance you'll actually have to implement your own BrowserBot just to download the pages.
The hints were littered everywhere that they did this.
Google does malware detection. Not on every crawl, but a certain percentage of crawls. At my old social network site, they detected malware that must have come from ad/tracking networks because those pages had no UGC. This suggests they were using Windows virtual machines (among others) and very likely using browsers other than a heavily modified curl / wget and a headless Chrome.
They started crawling the JavaScript-rendered version of the web and AJAX schemes that use URL shebangs. This was explicit acknowledgement that they were running JavaScript and did advanced DOM parsing.
They have always told people that cloaking (either to Google crawler IP blocks, user-agent, or by other means) content is a violation and they actively punished it. This suggests they do content detection and likely execute JavaScript to detect if extra scripts change the content of the page for clients that don't appear to be Googlebot.
They have long had measures in place to detect invisible text (eg. white text on white background) or hidden text (where HTML elements are styled over other HTML elements). This suggests both CSS rendering and JS rendering.
> At my old social network site, they detected malware that must have come from ad/tracking networks because those pages had no UGC. This suggests they were using Windows virtual machines (among others) and very likely using browsers other than a heavily modified curl / wget and a headless Chrome.
I think you're making a number of wild assumptions there. You can scan and detect malware without running Windows; and there's a whole gulf of different technologies between running desktop browsers and running a modified version of curl.
With regards to your browser point, normally I'd probably suggest that Google would be running node and making use of their own V8 Javascript engine to headlessly render the pages. However Google have the resources to build something much more bespoke so I think it would be foolish of me to make blind assumptions given how little I actually know about their internal technology.
> They have long had measures in place to detect invisible text (eg. white text on white background) or hidden text (where HTML elements are styled over other HTML elements). This suggests both CSS rendering and JS rendering.
No, this actually suggests it's not doing either. Both invisible and hidden text the way you've described it would be implemented with a CSS style. Not using that style would mean the text would appear as normal. I understand you probably meant that the JS was injecting the text in, which is fully possible, but that's neither hidden nor invisible text.
The parent is talking about them penalizing sites that use such hidden text that would normally show to the crawler but be invisible to an actual human looking at the page.
I don't know that I would go head-to-head with Google in crawling the entire web. However, I do see a lot of opportunities for "vertical search." That is -- search engines focused on specific, niche verticals (travel, healthcare, etc)
I'm working on a couple of projects in vertical search, and it is quite exciting. Sure, I'm building tech that Google had in 2005, but we are surprised with the results. We achieve search relevance simply by curating the sites we crawl (still in the thousands in some cases).
Do you have any links to share? I'm working on a side project for vertical search for programmers. Curating sites to crawl with source code, docs, mailing lists, QA, IRC and tutorials.
Trying to get away from the "W3Schools effect" [0], where outdated, terribly presented information or downright spammy pages are locked in the top results of Google by virtue of being around for so long, or by gaming search keywords [1].
I don't have anything public, but I have been exploring strategies for gluing together different tech in order to accomplish our goals. Latest stack has been:
- wget / wpull / heretrix to produce .warcs across a single domain - have a filewatcher on a folder to process .warc into text and then push it into elasticsearch with relevant metadata - flask search frontend for querying / results
Happy to share my learnings elsewhere. (I pinged you on email)
That was my first reaction as well. "We've engineered a competitive advantage so why don't you throw out that hard work the helps our competitors."
I'm not sure where I sit on this, developers who want to be noticed by other engines will continue to focus on SEO, but how many engineers care about SEO that isn't Google?
Honestly, optimizing sites for search is just wrong. It's happening now, because search is not perfect and developers have to work around its imperfectness. But in the ideal future, web masters must design websites for users, not for search engines, in the first and only place. That's what's happening now and it's good sign.
Of course Google competitors must work hard. I don't see why that's a bad thing. It's not like Bing or Yandex are going to disappear in the foreseeable future.
Depends what locale's you are targeting I am doing some strategy proposals for a client to help with their move into Asia.
Biaudu is one SE that doesn't crawl JS well from my research.
You can use one of the many headless browsers available. Selenium, phantomjs, phantomjs+casper, webkit, chromium, awesomium, name your poison. All are quite competent in rendering modern web pages. You don’t need to reinvent the wheel.
Also, if you want a headless browser that uses solely a JRE, my project is https://github.com/machinepublishers/jbrowserdriver
Any idea how good java's nashorn is for this.
Nashorn isn't actually used in Java's WebView (which my project leverages). Nashorn is used elsewhere in the JRE and replaces Rhino from prior releases, but WebView has used something else entirely: JavaScriptCore. Details: http://stackoverflow.com/questions/30104124/what-javascript-...
But essentially on performance, it's comparable to a desktop browser but still slower than I'd like. Java 9 should support HTTP 2 and async HTTP by default, which might help. And I've been looking into short-cutting some of the in-memory rendering but haven't had any breakthroughs yet.
As far as JavaScriptCore engine specifically, it's the default in WebKit so there should be good performance data out there on it.
Thanks
PhantomJS allows you to render a page and fully manipulate or search it. It's a headless WebKit browser you can use from the command line and it works pretty well. Google is obviously doing the same thing. They even used to show images of what a url looks like in the search results. They stopped doing that as I suspect it uses up a lot of resources of many sites.
I can say that Bing definitely does do JS interpretation as part of some of their renderings... I switched the URL routing in a relatively large site (about 300k routes, including navigatable search urls), so that they were all consistent, and all pointing to the new routes via permanent redirect... previously the project was supporting all of their older routing schemes over time, and it was troublesome wrt SEO (duplicated content on many pages, or the same because search parameters were the same, but different structure, same for individual content pages). When the change happened, we saw a huge uptick in google analytics hits (one page, no clickthroughs) coming from two locations... both turned out to be MS data centers. It was a relatively common problem.
It was always just a little white noise in the past, but when suddenly a couple hundred thousand pages permanently redirect... it was interesting.
> your own BrowserBot
So they're using headless browsers. Why can't anyone do that?
Scale
And perhaps security. I wouldn't be surprised if Google avoided standard C++/JIT browser engines in favor of something custom entirely written in a safe language - but if they don't, it wouldn't be that hard to get code execution on (a sandboxed portion of) Googlebot. Same goes for competitors - I don't think the state of public safe-language browsers is that good, though I'm not sure.
They are probably using virtual machines anyway, so it's not hard to set it up to simply load ram state for each new page they are crawling. This sidesteps the security issue (as long as there's no sandbox escapes).
It's possible they are using components from Google Chrome as others mentioned, like V8.
Wow, I built a project that rendered JS built webpages for search engines via NodeJS and PhantomJS. Rendering webpages is extremely CPU intensive, I'm amazed at the amount of processing power Google must have to do this at Internet scale.
I really hope this works, lots of JS libraries expect things like viewport and window size information, I wonder how Google is achieving that.
I'm wonder if they're cutting out a lot of the rendering that PhantomJS is doing. Not to say that any type of rendering is cheap but I'm guessing they have a limited version of a JS rendering engine that does just enough to index the page.
I bet they'd also skip on all the FB like buttons and other common social media elements that don't impact the content.
This makes sense. Would it be sufficient to just see how the content (eg new <ul> elements or something along those lines) on the page changes when JS is executed, without actually rendering anything?
They're starting to consider page load speed as a factor in rankings, which would lead me to believe that they're letting all the social buttons / trackers / media load.
How do you know a page has loaded? A complex page with ads, AJAX, WebSockets may be constantly busy. Most social buttons, ads, etc. are now loaded by callbacks, that usually finish after the page has rendered.
Most of that data flow, barring user interaction is much more limited compared to the initial load of controls, iframes, images, etc... you can visibly see the drop off..
If you look at the network tab in chrome dev tools, you can see when the dom ready event fires, the window load event, and when it really feels the content was done loading. That final load time is when the data flow lulls out for a bit.
Can confirm. Launched a project recently with over 500 concurrent PhantomJS workers. Let's just say my hosting bill is significantly more expensive than it was.
> lots of JS libraries expect things like viewport and window size information, I wonder how Google is achieving that.
Just plug in common screen parameters (e.g. 1920x1080, 1366x768, ...) and analyze it as if it were the result you'd get by default with Chrome on such a screen, I would imagine.
Same goes for user agent spoofing (to some extent). You can imagine most of the stuff when you use the chrome dev tools being done without actual user interaction.
Chrome is much lighter than phantomjs. I use Awesomium which is a .net port of Chromium and it loads pages at half the time phantom does with much less CPU load. My guess is that Google can refine it even further.
I'm wondering if Google is somehow, in some way, using the rendering data generated by the Chrome clients and/or Android to aid with processing power it takes to index everything.
More likely they're getting lots of data from analytics users for a great number of sites as it is, and only really need to do custom renders for load time analysis for some sites, and not necessarily all pages... to a larger extent, I'm pretty sure they could have an optimized rendering pipeline for a headless chrome that actually works better than, by comparison, phantomjs.
I think they might mitigate the need to crawl _every_ page of every web site in that fashion. They must be doing some sort of analysis to "old-school-crawl" pages that don't need javascript interpretation.
What if they don't actually "render" the dom as part of the "load" analysis... this means they don't necessarily need to handle certain UI/UX aspects that can be bypassed.. they could then output the "rendered" content for passthrough to the same system that does their general crawl analysis for additional details.
The work could be broken up in any number of ways... from my own testing, and experience with others testing. Content crawls/recrawls from JS data tends to lag a couple days behind initial scan... having an updating sitemap xml resource is a good idea for "new" content if you're doing JS based content.. also, rescans will still lag well behind the general non-js content scans...
The viewport and window size is probably just for browser fingerprinting. Google probably just grabs the text, and has a pretty efficient fingerprinting system.
The XHTML+XSLT+XML-FO stack produced pages that took 3x-10x less CPU to render. But that's dead of course.
> The XHTML+XSLT+XML-FO stack produced pages that took 3x-10x less CPU to render. But that's dead of course.
Was it ever alive? I never found a decent browser XSL-FO renderer, there were some that seemed kind of proof-of-concept-ish (the only decent XSL-FO rendering I ever encountered was intended for print-like media, mostly PDF, rather than for browsing.)
This is good-one of my current projects for a customer is entirely AJAX/JS rendered and we were worried that Googlebot would have a fit with it.
You should still be worried. Just because googlebot expensively evaluates JS for some websites doesn't mean it will evaluate JS for your brand-new website. You might get crawled a lot less deeply than if you had good content in your static pages.
By abandoning their AJAX crawling scheme as described in the OP, they are essentially saying that they will evaluate JS for all sites. Do you have some reason to doubt that?
If crawling with JS costs 1,000X or 10,000X as much as crawling without, it's fair to say that even Google isn't going to crawl 100s of billions of pages executing JS.
As a former web-scale search engine CTO, my opinions are commonly surprising to folks who haven't built a web-scale crawler/search engine.
My own experiments/experience shows that recrawls happen about 1/3 as often and tend to lag a few days behind for JS content vs inlined/delivered content. It's helped a little by dynamically delivering the sitemap data, but even that only speeds things up a little.
My guess is they're putting about 1/10th the effort into keeping things freshly indexed for JS, but may well be devoting 2x the resources vs directly received content.
> By abandoning their AJAX crawling scheme as described in the OP, they are essentially saying that they will evaluate JS for all sites.
No, they are not. If you even think that's possible you're fundamentally misunderstanding how search engines work.
About a year ago I wrote a post[1] about how I couldn't get google to index my AngularJS app. My main problem was the interaction between googlebot and the S3 server. I'll have to go back and test if the crawler's behavior will render the correct content.
1 - https://medium.com/@devNoise/seo-fail-figuring-out-why-i-can...
Do you have a sitemap.xml for common routes.. also is your angular app actually doing routing (hash based or push state)?
I have the .html5Mode set to true so it was routing based on push state.
I hadn't gotten around to creating a process to generate the sitemap.xml before I gave up on the site. For SEO, we were more concerned with getting the time sensitive content indexed.
We recently built a site for a customer in Ember and their SEO guys were concerned about indexing. I wasn't sure how it was going to work out, but in the end Google has been able to index every page no problem.
Do you know if they sent Google a sitemap? Our client is insisting on a sitemap that has pointers to every-single-product. Something on the order of 2MM+ product pages. It seems like a bit much to me
Keep this in mind https://support.google.com/webmasters/answer/183668?hl=en&to...
> Break up large sitemaps into a smaller sitemaps to prevent your server from being overloaded if Google requests your sitemap frequently. A sitemap file can't contain more than 50,000 URLs and must be no larger than 50 MB uncompressed.
The site is built on Tumblr which automatically generates a sitemap for the individual posts, but not any other pages on the site. For example the "about" page is not in the sitemap, but is still indexed.
Sorry if this is a stupid question as this is outside my field of work, but how can you tell if your page has been successfully indexed or not?
See https://www.google.com/webmasters/tools/ for index stats, error reports, etc.
Just search on google for "site:http://www.yoursite.com" and you can see the pages it has indexed.
How many pages does the site have?
This was the missing piece for Polymer elements / custom web components. Now that Google has confirmed it's indexing JavaScript, web-component adoption should take off.
I want to like polymer/web-components... I just find that it kind of flips around the application controls that redux+react offers. I'm not sure that I like it better in practice.
Gary Illyes @goog said this was happening Q1 this year, and like others mentioned lots of other direct/indirect signals have pointed this way.
http://searchengineland.com/google-may-discontinue-ajax-craw... March 5th: Gary said you may see a blog post at the Google Webmaster Blog as soon as next week announcing the decommissioning of these guidelines.
Pure speculation but interesting... The timing may have something to do with Wix, a Google Domains partner, who is having difficulty with their customer sites being indexed. The support thread shows a lot of talk around "we are following Google's Ajax guidelines so this must be a problem with Google". John Mueller is active in that thread so it's not out of the realm of possibility someone was asked to make a stronger public statement. http://searchengineland.com/google-working-on-fixing-problem...
I'm betting that they finally solved the scalability problems with headless WebKit. Google's been able to index JS since about 2010, but when I left in 2014, you couldn't rely on this for anything but the extreme head of the site distribution because they could only run WebKit/V8 on a limited subset of sites with the resources they had available. Either they got a whole bunch more machines devoted to indexing or they figured out how to speed it up significantly.
I'd say both are pretty likely.. another round of lower-power servers with potentially more cores... more infrastructure... Combined with improvements in headless rendering pipelines. I haven't looked into it in well over a year now, but last I checked dynamic updates took about 2-3 days to get discovered vs. server-delivered being hours for a relatively popular site.
I'm guessing they've likely cut this time in half through a combination of additional resources, and performance improvements. Wondering if they'd be willing to push this out as something better than PhantomJS... probably not as it's a pretty big competative advantage.
I know MS has been doing JS rendering for a few years, they show up in analytics traffic (big time if you change your routing scheme on a site with lots of routes, will throw off your numbers).
Currently I use prerender.io and this meta tag:
<meta name="fragment" content="!">
Does this announcement mean I can remove the <meta> tag and stop using prerender.io now?
If Google Webmaster Tools is unable to render your website correctly, then that's a good indicator that Googlebot won't be able to render the pages correctly either. If you remove the fragment meta tag, then Google will need to render your javascript to see the page. Let us know how that goes if you try it! todd@prerender.io
We have a similar setup and were wondering the same thing (though we use push state). Today we were actually trying to figure out a workaround for 502s and 504s that google crawler was seeing from prerender. We just took the plunge and removed the meta tag because over 99% of our organic search traffic is from google. Fingers crossed!
I'd love to help here if I can. I'd also love to hear the results of you removing the meta tag! todd@prerender.io
Any idea how related this might be to Wix sites getting de-indexed?[1]
http://searchengineland.com/google-working-on-fixing-problem...
This might be obvious to anyone who has done SEO, but can Googlebot index React/Angular websites accurately? I was always under the impression that the isomorphic aspect of React helped with SEO (not just load times.)
If a modern browser can render your site accurately, then Google can index it.
It's always lagged in my experience... I'm hoping this announcement means that lag is under a day instead of the 2-3 it was a bit over a year ago.
Finally. It was obvious we would have to get to that point eventually, it just wasn't clear when.